1 说明
1.1 Tesseract
1.1.1 是目前公认最优秀、最精确的开源 OCR 系统。
1.1.2 目前由 Google 赞助。
1.1.3 优点:极高的精确度,很高的灵活性,还可以通过训练识别出任何字体,也可以识别出 Unicode 字符。
1.2 python的tesseract进行有关库:有2个。
1.2.1 tesserocr和pytesseract是Python的2个OCR识别库。
1.2.2 tesserocr和pytesseract的核心都是tesseract。
1.3 内容
1.3.1 tesseract,tesserocr和pytesseract的安装。
1.3.2 基本使用教程,入门级,讲解清楚,一秒入门,适合收藏。
2 tesseract安装
2.1 本机是deepin-linux操作系统,安装方法如下:
#在Ubuntu、Debian和Deepin系统下,安装命令如下:sudo apt-get install -y tesseract-ocr libtesseract-dev libleptonica-dev
2.2 查看默认安装语言:没有中文
tesseract --list-langs
结果:
List of available languages (3):osdengequ
2.3 中文等语言包的安装:
2.3.1 方法一:
git clone https://github.com/tesseract-ocr/tessdata.git #我失败了,你懂的
2.3.2 方法二:
https://github.com/tesseract-ocr/tessdata #网页手动下载,我竟然也失败了
2.3.3 方法三:
自己网上搜索下载,好心人的资源,我成功了,自己找吧,有的,我这里就不放了。
2.3.4 将下载的语音包解压,复制到/usr/share/tesseract-ocr/tessdata下。
2.4 再查看一下能支持的语言包,可以支持129种语言了。

3 tesseract的使用
3.1 终端:
tesseract /home/xgj/Desktop/tesserocr/1.png /home/xgj/Desktop/tesserocr/output-1
3.2 说明:1.png识别的文字的图片,生成output-1.txt文件,默认英文识别。
3.3 注意:识别图片不能太小。
Error in pixGenerateHalftoneMask: pix too small: w = 150, h = 52
3.4 中文识别,-l chi_sim代表语言为中文简体。
tesseract /home/xgj/Desktop/tesserocr/4.png /home/xgj/Desktop/tesserocr/output-4 -l chi_sim
4 python的tesseract封装库
4.1 安装:
pip install tesserocr pillow #默认附带安装pillow读取图片pip install pytesseract #同上,实际工作中,安装一个就可以了,使用相同
4.2 识别图

4.3 pytesseract的使用
4.3.1 效果图

4.3.2 代码
import pytesseract# 【注意】PIL库的安装: pip install Pillowfrom PIL import Image# 读取图片image = Image.open("/home/xgj/Desktop/tesserocr/5.png")# 识别图片a=pytesseract.image_to_string(image, config="-psm 7",lang='chi_sim')#打印结果print(a)
4.4 tesserocr使用,代码如下:
import tesserocr#可识别中文#方法一print(tesserocr.file_to_text('/home/xgj/Desktop/tesserocr/5.png',lang='chi_sim'))#方法二from PIL import Image#读取图片image = Image.open('/home/xgj/Desktop/tesserocr/5.png')print(tesserocr.image_to_text(image,lang='chi_sim'))
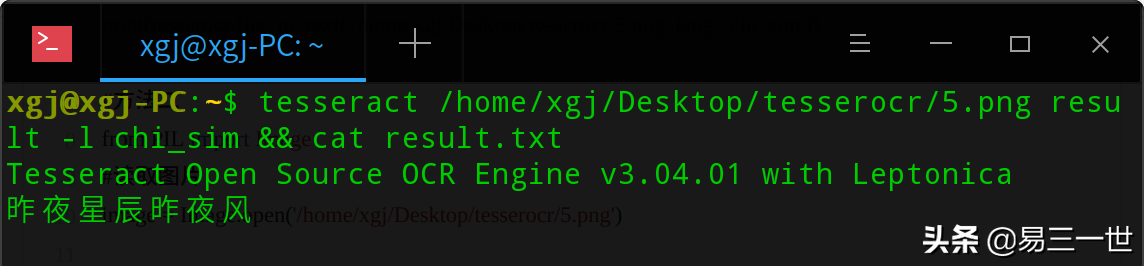
5 补充一下终端法:
tesseract /home/xgj/Desktop/tesserocr/5.png result -l chi_sim && cat result.txt