
前言
正则表达式作为一名合格的程序员的必备的基本技术之一,其有用性不言而喻。但是它为什么会非常难以掌握,甚至想用一用也都感觉难以下手呢?本文将会让你一次就看会如何使用Python正则表达式。
1. 正则表达式的组成
在介绍如何使用Python的正则表达式时,我们需要先认识一下正则表达式的各种功能,以及其组成形式如何。
正则表达式可以从非结构化的文本中提取到我们想要的内容,其本质为模式匹配,也是体现出智能化的最初手段,现在已经广泛应用于自动化处理信息的流程之中,从爬虫到人工智能,无处不在,其需求也是相当的大。
一提及正则表达式的编写,在N多的博客里都提到了一个神奇的网站http://www.txt2re.com/,这个网站我之前也用过,如果你不会正则表达式,又想偷懒自动生成,你只需要在这个网站里复制粘贴一个最复杂的情况,然后把你想匹配的内容通过可视化的点击组合就可以自动生成你想要的正则表达式。
但是遗憾的是,这个网站目前已经打不开了。这也正是告诉我们,核心技术掌握在自己手里才是真啊。现在我们来看看正则表达式该如何编写。下面是使用进行正则表达式的一般流程,不同的语言其实现方法不完全相同,我们今天主要聚焦与使用python进行正则表达式的三种匹配方式,以获得我们想要的目标片段,对于其他方法,我们以后再进行讲解。
首先确定你的输入的大致格式
在这个输入的大致格式中定位到你需要的内容,以及你不需要的内容。
通过正则表达式将其匹配出来
抽取其临时的结果将其保存到我们需要的数据结构中
2. 使用python表示正则表达式流程
如果我们使用python进行一个正则表达式正则时,我们主要经历一下几个步骤:
导入包
根据需求指定正则表达式
编译自定义的表达式
根据其表达式进行匹配
输出结果
1,3,5都是相对容易的部分,而其中最难的部分主要有两步,一个是制定一个符合需求的正则表达式,另一个则是如何进行匹配。我们最后会简单的介绍一下输出结果。
3. 编写正则表达式
编写正则表达式是其中的核心,如何编写正确的,符合我们想法的表达式呢?我们这里介绍下面两个部分进行构建:
原封不动的单词
这一部分并不是我们需要的,只是一些留存在我们需要的内容中间的部分。原封不动的单词就原封不动的抄写上去,不要增加格外的形式。
待匹配的部分
这一部分使我们想抽取出的内容,将我们想匹配的部分使用正则表达式进行表达分为两个部分,一个部分为我们的匹配的字符,例如:
w 匹配字母数字及下划线W 匹配非字母数字及下划线s 匹配任意空白字符,等价于 [tnrf].S 匹配任意非空字符d 匹配任意数字,等价于 [0-9].D 匹配任意非数字A 匹配字符串开始Z 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。z 匹配字符串结束G 匹配最后匹配完成的位置。b 匹配一个单词边界,也就是指单词和空格间的位置。例如, ‘erb’ 可以匹配"never" 中的 ‘er’,但不能匹配 “verb” 中的 ‘er’。B 匹配非单词边界。‘erB’ 能匹配 “verb” 中的 ‘er’,但不能匹配 “never” 中的 ‘er’。n, t, 等. 匹配一个换行符。匹配一个制表符。等1…9 匹配第n个分组的内容。10 匹配第n个分组的内容,如果它经匹配。否则指的是八进制字符码的表达式。另一种,则是匹配的模式,决定我们如何进行匹配:^ 匹配字符串的开头$ 匹配字符串的末尾。. 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。[…] 用来表示一组字符,单独列出:[amk] 匹配 ‘a’,‘m’或’k’[^…] 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。re* 匹配0个或多个的表达式。re+ 匹配1个或多个的表达式。re? 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式re{ n} 精确匹配 n 个前面表达式。例如, o{2} 不能匹配 “Bob” 中的 “o”,但是能匹配 “food” 中的两个 o。re{ n,} 匹配 n 个前面表达式。例如, o{2,} 不能匹配"Bob"中的"o",但能匹配 "foooood"中的所有 o。“o{1,}” 等价于 “o+”。“o{0,}” 则等价于 “o*”。re{ n, m} 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式a| b 匹配a或b(re) 对正则表达式分组并记住匹配的文本(?imx) 正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域。(?-imx) 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域。(?: re) 类似 (…), 但是不表示一个组(?imx: re) 在括号中使用i, m, 或 x 可选标志(?-imx: re) 在括号中不使用i, m, 或 x 可选标志(?#…) 注释.(?= re) 前向肯定界定符。如果所含正则表达式,以 … 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。(?! re) 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功(?> re) 匹配的独立模式,省去回溯。
两者搭配即可完成我们想要的结果,虽然这里列举了很多,但是我们常用的就那几个,正则表达式的简单划分将正则表达式划分为元字符、反义、量词和懒惰限定词。我会在后面的部分给出一个实例。当我们的正则表达式撰写完毕后,我们使用下面的函数获得我们的匹配模板。
re.compile(pattern[, flags])
4. 匹配的方式
正则表达式匹配的方式主要有3种match, search和findall。如果你懂英语的话,就知道它们的区别,这里前两个都是单一匹配,只会匹配一个流程,如果有多个符合匹配规则的,它们只会返回第一个结果,而findall会把所有符合候选的都匹配出来。而前两个的区别就是match必须是开头就要能够匹配,也就是和startwith差不多的效果,而search则可以在任意位置进行匹配。
下面看一下三个方法的参数表示,其中pattern为我们制定的正则表达式,string为我们要匹配的字符串,flags表示匹配模式:
re.match(pattern, string, flags=0)re.search(pattern, string, flags=0)findall(string[, pos[, endpos]])
因此我们选择方式时有以下几个步骤:
是否需要匹配多个?是,选择findall
是否需要从头匹配?是,选择match
一般情况使用search
5. 匹配结果展示
匹配结果展示主要有以下四个部分组成:
group([group1, …]) 方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用 group() 或 group(0);start([group]) 方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为 0;end([group]) 方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数默认值为 0;span([group]) 方法返回 (start(group), end(group))。例如下面这个例子,主要表现了我们如何调用这四个部分。>>>import re>>> pattern = re.compile(r'd+') # 用于匹配至少一个数字>>> m = pattern.match('one12twothree34four') # 查找头部,没有匹配>>> print mNone>>> m = pattern.match('one12twothree34four', 2, 10) # 从'e'的位置开始匹配,没有匹配>>> print mNone>>> m = pattern.match('one12twothree34four', 3, 10) # 从'1'的位置开始匹配,正好匹配>>> print m # 返回一个 Match 对象<_sre.SRE_Match object at 0x10a42aac0>>>> m.group(0) # 可省略 0'12'>>> m.start(0) # 可省略 03>>> m.end(0) # 可省略 05>>> m.span(0) # 可省略 0(3, 5)
6. 举一个简单的例子
一个更好的,更直观易懂的方法是如下这个例子,相比较刚才使用数字索引,它将每一个匹配内容语义化,使得代码更加容易理解。contactInfo = ' ( Nucleus (span 2 3) (rel2par span)'pattern=re.compile(r'(?P<nuclearity>w+) (span (?P<start>w+) (?P<end>w+)) (rel2par (?P<relation>w+))')match = pattern.search(contactInfo)print(match.group()) # Nucleus (span 2 3) (rel2par span)print(match.group("nuclearity")) # Nucleus print(match.group("start")) # 2print(match.group("end")) # 3print(match.group("relation")) # span
从上述的例子中我们就可以获得最直观的结果,我们只需要将这些结果存入到我们需要的数据结构中即可。
7. 其他一些补充知识
7.1 匹配常用的一些格式
如果我们只需要匹配一些常用的格式,如姓名、身份证、邮箱、电话号码等,都是有现成的工具直接生成,不需要我们进行再次编写。
7.2 匹配中文字符
如果你只是想匹配若干个中文汉字,使用下面的正则表达式:
[u4E00-u9FA5\s]+ 多个汉字,包括空格[u4E00-u9FA5]+ 多个汉字,不包括空格[u4E00-u9FA5] 一个汉字
这里还有匹配更全的中文字的方法。
提到用正则表达式匹配汉字,很容易搜到这个[u4e00-u9fa5],但是它不算全面,不包含一些生僻汉字。
本文对此问题做一个梳理。
以下是比较全面的汉字Unicode分布,参考Unicode 10.0标准(2017年6月发布):
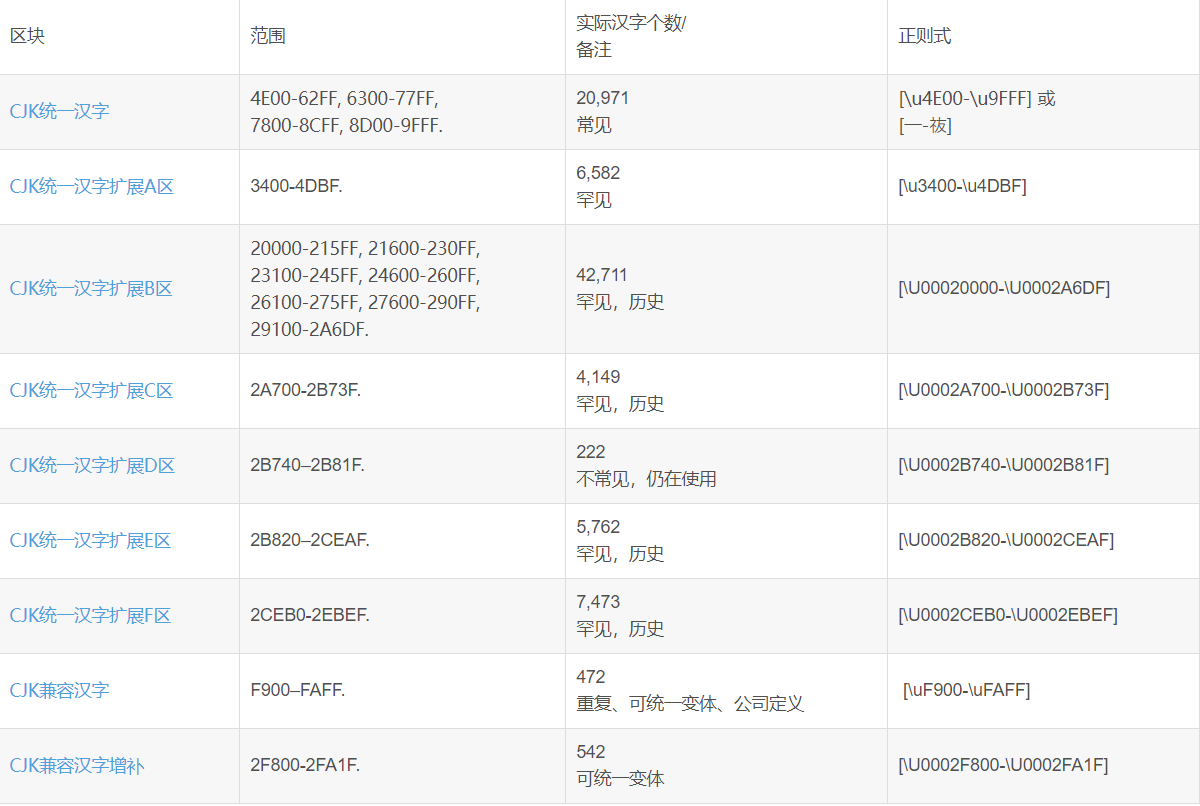
★ 如果想表示最普遍的汉字,用:
[u4E00-u9FFF] 或 [一-鿆]
共有20950个汉字,包括了常用简体字和繁体字,镕等字。
基本就是GBK的所有(21003个)汉字。也包括了BIG5的所有(13053个)繁体汉字。
一般情况下这个就够用了。
说明:
仅仅未包括出现在GBK里的CJK兼容汉字的21个汉字:郎凉秊裏隣兀嗀﨎﨏﨑﨓﨔礼﨟蘒﨡﨣﨤﨧﨨﨩
CJK兼容汉字用于转码处理,日常中是用不到的,所以不包括也没什么问题。
注意此凉非彼凉,兀也不是常用的那个,虽然用眼睛看是一样的,参见http://www.zhihu.com/question/20697984
★ 如果想表示BMP之内的汉字,也就是Unicode值<=0xFFFF之内的所有汉字,用:
[u4E00-u9FFFu3400-u4DBFuF900-uFAFF]
这个包含但不限于GBK定义的汉字,共有28025个汉字。
说明:
和上面相比,主要是多了CJK统一汉字扩展A区,这是1999年收录到Unicode 3.0标准里的6,582个汉字。
CJK统一汉字扩展A区,包括了东亚各地区(陆港台日韩新越)的汉字,有很多康熙字典的繁体字。
★ 如果想尽可能表示所有的汉字,用:
[u4E00-u9FFFu3400-u4DBFuF900-uFAFFU00020000-U0002EBEF]
这个包含上表的所有88342个汉字
说明:
1, 以上正则表达式不会匹配(英文、汉字的)标点符号,不会匹配韩国拼音字、日本假名。
2, 会匹配一些日本、韩国独有的汉字。
3, 包含了一些没有汉字的空位置,这通常不碍事。
4, u及U的正则语法在Python 3.5上测试通过。
有些正则表达式引擎不认uFFFF和UFFFFFFFF这样的语法,可以换成x{FFFF}试一下;有些不支持BMP之外的范围,这就没办法处理CJK统一汉字扩展B~E区了,如notepad++。
7.3 匹配一些特殊符号
正则表达式的各种括号的用处以及如何进行括号的匹配。
匹配小括号中的内容
import restring = 'shain(love)fufu)'p1 = re.compile(r'[(](.*?)[)]', re.S) #最小匹配p2 = re.compile(r'[(](.*)[)]', re.S) #贪婪匹配print(re.findall(p1, string))print(re.findall(p2, string))
输出:
[‘love’]
[‘love)fufu’]
匹配中括号中的内容
import restring = 'shain[胖妮shain和傻夫夫fufu]fufu)'p =r'[[][Ww]+[]]'print(re.findall(p, string))
输出:
[’[胖妮shain和傻夫夫fufu]’]
匹配大括号中的内容
import restring = "shain,fsf{傻夫夫,grr},胖妮{fsf,1201}"p = re.findall(r'({.*?})', string)print(p)
输出:
[’{傻夫夫,grr}’, ‘{fsf,1201}’]



