
一 初识HBase
1.1 HBase的概念
HBase是一分布式的、面向列的开源NoSQL海量数据库存储系统,它的理论原型是 Google 的 BigTable 论文。通俗地讲,HBase 是一个具有高可靠性、高性能、面向列、可伸缩的分布式存储系统。它可以处理分布在数千台服务器上的PB级海量数据。
HBase是基于HDFS存储数据的,HDFS是部署在商业服务器上的,并且具有高容错性。基于HDFS,就意味着HBase具有超强的扩展性和容错性。
在详细介绍HBase之前,我们一起来看看HBase的架构,如下图所示: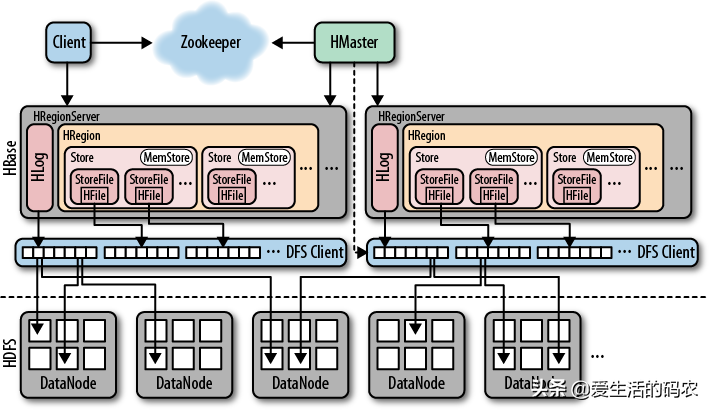
HBase的系统架构
HBase采用的是key/value的存储格式,这就能保证,即使数据量增大,也不会导致查询性能大幅度下降。因为 HBase 是一个面向列存储的数据库,当表的字段很多时,可以把其中几个字段放在一部分机器上,而另外几个字段放到另一部分机器上,充分分散负载的压力。如此复杂的存储结构和分布式存储方式,带来的代价就是即便是存储很少的数据,也不会很快。
我们可以看出,HBase是那种既不快,又慢的不明显的数据库,因此,它主要应用在以下两种情况的查询:
单表数据量不能太大(千万级别),并发量不能太高。对数据需求分析不要求特别及时,同时也不要求太灵活。
二 HBase简介
2.1 HBase自身的优势
2.1.1 海量存储数据
因为HBase是基于Hadoop存储的,所以,HBase适合存储 PB 级别以上的海量数据,可以部署在普通廉价商用服务器上,能够在几十到百毫秒内返回数据。这都得力于HBase的良好扩展性,为海量数据的存储提供了便利。
2.1.2 列式存储数据
HBase是根据列族来存储数据的。列族下面可以有非常多的列,在建表时,必须指定列族,但是不用指定列。
2.1.3 稀疏性存储结构
稀疏主要体现在HBase的列的灵活性上面,在HBase的列族中,可以指定任意多的列,在列数据为空的情况下,HBase表是不会占用存储空间的。
2.1.4 易扩展性
一个是基于上层处理能力(RegionServer)的扩展,通过横向添加 RegionSever 的机器,进行水平扩展,提升 HBase 上层的处理能力,提升HBase服务更多 Region 的能力。另外一个是基于存储能力(HDFS)的扩展。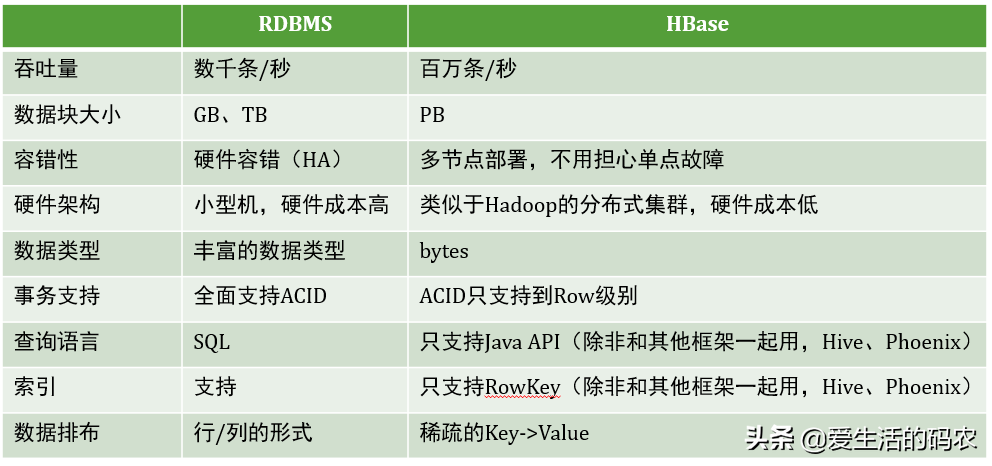
HBase和数据库的比较
2.2 HBase的逻辑结构
在下图中,列簇(Column Family)对应的值就是 info 和 area ,列( Column 或者称为 Qualifier )对应的就是 name 、 age 、 country 和 city ,Row key 对应的就是 Row1 和 Row2,Cell 对应的就是具体的值。
Row key :表的主键,按照字典序排序。列簇:在 HBase 中,列簇将表进行横向切割。列:属于某一个列簇,在 HBase 中可以进行动态的添加。Cell : 是指具体的 Value 。Version :在这张图里面没有显示出来,这个是指版本号,用时间戳(TimeStamp )来表示。
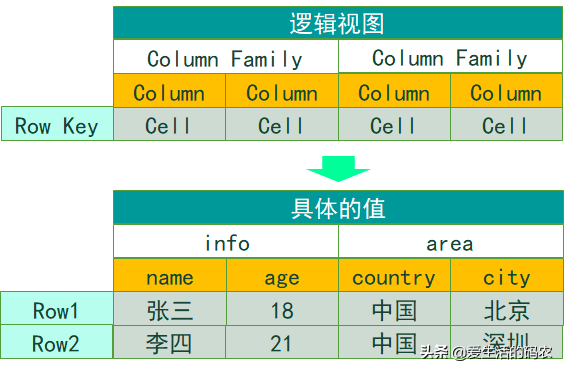
HBase的逻辑结构
看完这张图,是不是有点疑惑,怎么获取其中的一条数据呢?既然 HBase 是 KV 的数据库,那么当然是以获取 KEY 的形式来获取到 Value 啦。在 HBase 中的 KEY 组成是这样的:
cell的结构
KEY 是由 Row key 、CF(Column Family) 、Column 和 TimeStamp 组成的。
TimeStamp 在 HBase 中的作用就是版本号,因为在 HBase 中有着数据多版本的特性,所以同一个 KEY 可以有多个版本的 Value 值(可以通过配置来设置多少个版本)。查询的话是默认取回最新版本的那条数据,但是也可以进行查询多个版本号的数据。
2.3 HBase的物理结构
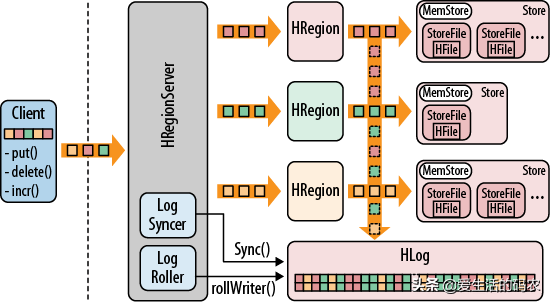
HBase的物理结构
2.3.1HRegionServer
HRegionServer 就是一个机器节点,包含多个 HRegion ,但是这些 HRegion 不一定是来自于同一个 Table。直接面对用户的读写请求,是真正干活的节点。它的主要功能如下:
为Table分配HRegion。处理来自客户端的读写请求,和底层的HDFS进行交互,并将数据存储到HDFS中。负责单个HRegion变大后的拆分。负责StoreFile的合并工作。
ZooKeeper会监控HRegionServer的上下线情况,当ZK发现某个HRegionServer下线之后,会告知Master进行失效处理。下线HRegionServer以及他负责的HRegion暂时对外提供服务,Master会将该HRegionServer所负责的HRegion转移到其他HRegionServer上。
2.3.2 HRegion
每一个HRegion都包含多个Store,一个Store就对应一个列族的数据,而一个Store可以有多个StoreFile。HRegion 是 Hbase 中分布式存储和负载均衡的最小单元,但不是存储的最小单元。每一个HRegion都有开始的RowKey和结束的RowKey,代表着存储的Row的范围。
2.3.3 Store(文件存储区)
Store 对应着的是 Table 里面的 Column Family,不管有 CF 中有多少的数据,都会存储在 Store 中,这也是为了避免访问不同的 Store 而导致的效率低下。一个 CF 组成一个 Store ,默认是 10 G,如果大于 10G 会进行分裂。Store 是 HBase 的核心存储单元,一个 Store 由 MemStore 和 StoreFile 组成。
2.3.3.1 MemStore
每个Store都包含一个MEMStore实例,MemStore是内存的存储对象,当 MemStore 的大小达到一个阀值(默认大小是 128M)时,如果超过了这个大小,那么就会进行刷盘,把内存里的数据刷进到 StoreFile 中,即生成一个快照。目前HBase 会有一个线程来负责MemStore 的flush操作。
2.3.3.2StoreFile
StoreFile底层是以 HFile 的格式保存数据。
2.3.4 StoreFile和HFile的物理结构
StoreFile 以 HFile 格式保存在 HDFS 上,HFile 文件是不定长的,长度固定的只有其中的两块:Trailer 和 FileInfo。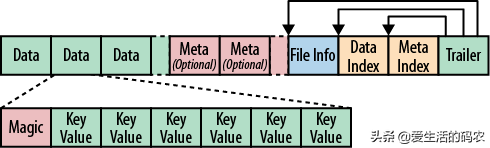
StoreFile的物理结构
HFile 里面的每个 KeyValue 对就是一个简单的 byte 数组。但是这个 byte 数组里面包含了很 多项,并且有固定的结构。
HFile的物理结构
分别表示Key 的长度和 Value 的长度。紧接着是RowKey 的长度,紧接着是 RowKey,然后是 Family 的长度,然后是 Family,接着是 Qualifier,然后是两个固定长度的数值,表示 Time Stamp 和 Key Type(Put/Delete)。Value 部分没有这么复杂的结构,就是纯粹的二进制数据了。
三 HBase的底层架构
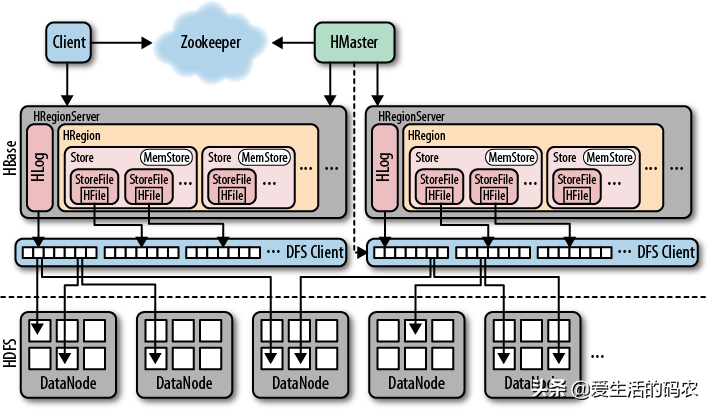
HBase的底层架构
从HBase的架构图上可以看出,HBase中的组件包括Client、Zookeeper、HMaster、HRegionServer、HRegion、Store、MemStore、StoreFile、HFile、HLog等。
3.1 Client
Client在访问HBase之前,先访问ZooKeeper找到数据所在的HRegion。Client中有访问HBase的接口,另外Client还维护了对应的Cache来加速HBase的访问,比如缓存元数据。
3.2 ZooKeeper
① HBase 通过ZooKeeper来做 Master 的高可用
通过ZooKeeper来保证集群中只有一个Master在运行,为HBase提供了Failover机制,如果Master发生意外会通过竞争机制产生选举新的Master,避免Master节点的单点故障问题。
② 通过ZooKeeper监控HRegionServer的状态,当HRegionServer有异常,或者有新的HRegionServer上线时,会通过回调方式告诉MasterRegionServer有节点的上下线信息
③ 存储HBase的Schema,包括有哪些Table,每个Table有哪些Column Family信息。
3.3MasterRegionServer
Master 是集群的主节点,可以配置成HA的形式。Master 的工作并不高,因为Client 访问 HBase 上数据的过程并不需要 Master 参与(寻址访问 zookeeper 和 RegioneServer,数据读写访问 RegioneServer),Master 的负载很低。他的主要工作如下:
负责HRegionServer的负载均衡。发现失效的HRegionServer之后,将该HRegionServer上的Region分配给其他HRegionServer。为HRegionServer分配Region。负责HDFS上的HBase的垃圾文件的回收。维护Table和Region的元数据,处理 Schema 更新请求(表的创建,删除,修改,列簇的增加等等)
3.3 HRegionServer
HRegionServer的功能参见 2.3.1 HRegionServer
3.4 HRegion
HRegion的功能参见 2.3.2 HRegion
3.5 Store
Store的功能参见 2.3.3 Store
3.6 HFile
HFile是存储在HDFS中的二进制文件,实际上,StoreFile就是对Hfile做了轻量级包装,StoreFile底层是HFile。
3.7 HLog
HLog(WAL log):WAL(Write-Ahead-Log)意为预写日志,在 RegionServer 在插入和删除数据的过程中,用来记录操作内容的一种日志,主要用来做灾难恢复使用,HLog记录数据的所有变更,一旦region server 宕机,就可以从log中进行恢复。
WAL是保存在HDFS上的持久化Hadoop Sequence File文件。数据到达 Region 时先写入WAL,然后被加载到MemStore中。这样就算Region宕机了,操作没来得及执行持久化,在重启的时候从WAL开始加载数据并执行。跟Redis的AOF类似。
在每个HRegionServer上,所有的HRegion都共享一份HLog,在写入数据时先写入WAL,成功之后再写入MemStore。当MemStore的大小达到一个阀值(默认大小是 128M)时,就会形成一个一个的StoreFile。WAL的状态是可以关闭的,关闭之后增删改的操作会快一些,但是会牺牲掉数据的可靠性。当然,我们也可以采用异步的方式写入WAL(默认间隔是1秒钟)。HBase中的WAL文件是一个滚动日志数据结构,一个WAL实例包含多个WAL文件,在WAL的大小超过一定的阀值,或者WAL所在的HDFS文件块要满了的时候,WAL会触发滚动操作。
四 HBase的读写机制
我们在对HBase进行读写操作的时候,不需要和HMasterRegionServer打交道。客户端只需要从ZooKeeper中获取HBase表数据的地址,然后直接从HRegionServer中进行读写操作。
4.1 HBase读数据过程
客户端通过 ZooKeeper 集群,根据-ROOT-表和.META.表,找到目标数据所在的 RegionServer(就是要找到数据所在的 Region 的主机地址)与目标的 RegionServer 进行通信,查询目标数据。RegionServer 定位到目标数据所在的 Region,发出查询请求。Region 分别在Block Cache(读缓存),Memstore 和StoreFile(HFile)中查找目标数据,并将查询到的所有数据进行合并,此处的所有数据是指,同一条数据包含不同的版本(Timestamp)的数据。将从HFile中查询到的数据块(Block,HFile的数据存储单元,默认大小是128MB)缓存到Block Cache中,然后将最新的数据返回给客户端。
Data Block 是HBase读写的基本单元,为了提高查询效率,HRegionServer 基于 LRU 的 Block Cache 机制进行读操作。HBase的读取数据的机制是:HBase 同时读取磁盘和内存中的数据,然后把磁盘上的数据放到 BlockCache中,BlockCache 是磁盘数据的缓存。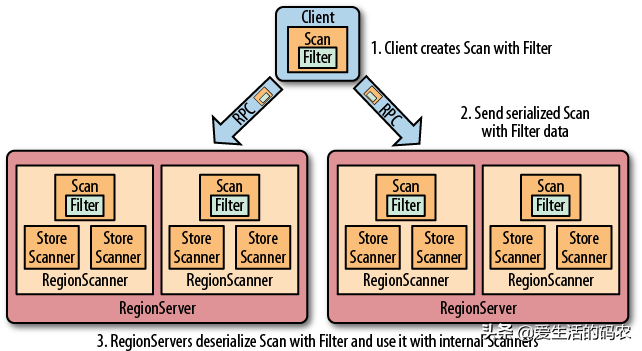
HBase的读机制
4.2 HBase写数据过程
Client 先访问ZooKeeper,根据 RowKey 查询目标数据位于哪个RegionServer对应的 Region 中。Client 向目标RegionServer 进行通信,并提交写请求。RegionServer 找到目标 Region,Region 检查数据的格式是否与 Schema 一致。如果客户端没有指定版本,则获取当前系统时间作为数据版本。将数据顺序写入(追加)到 WAL Log将数据更新写入 Memstore,数据会在MemStore中排序。判断 Memstore 的是否需要 flush 为 StoreFile 文件。
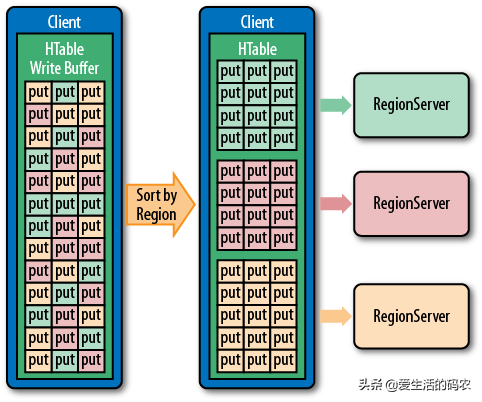
HBase的写机制
4.3 HBase的写为什么比读快
HBase能够提供实时计算服务的根本原因是其架构和底层数据结构决定的,Hbase底层的存储引擎为LSM-Tree(Log-Structured Merge-Tree)。
LSM的核心思想是放弃部分读能力,换取写入的最大化能力。LSM的原则就是,先将最新的数据驻留在内存中,等到积累足够多时,再使用归并排序的方式将内存中的数据追加都磁盘的队尾。另外,LSM的写入是磁盘的顺序写,数据写入速度也很稳定。我们知道磁盘的顺序写和内存写性能相差不大,但是顺序写磁盘速度要比随机写磁盘快至少三个数量级!
不过读取的时候稍微麻烦,需要合并磁盘中历史数据和内存中最近修改操作,这样磁盘在寻址耗时就远远大于磁盘顺序读取的诗句;另外数据读操作的时候,还要看数据在内存中是否命中,否则需要访问更多的磁盘文件。基于LSM树实现的HBase的写性能比MySQL高一个数量级,但是读数据的性能要比MySQL低一个数量级。
LSM树原理把一棵大树拆分成N棵小树,它首先写入内存中,随着小树越来越大,内存中的小树会flush到磁盘中,磁盘中的树定期可以做merge操作,合并成一棵大树,以优化读性能。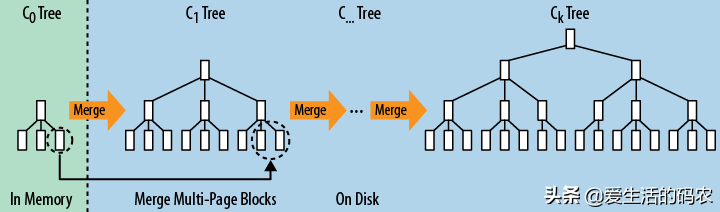
LSM树
补充:LSM-Tree全称是Log Structured Merge Tree,是一种分层有序,面向磁盘的数据结构,其核心思想是充分了利用了,磁盘顺序写要远比随机写性能高出很多的特性,如下图示: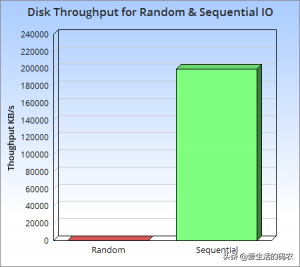
随机性和顺序写的性能比对
围绕LSM-Tree的原理进行设计和优化,以此让写性能达到最优,当然有得就有舍,这种结构虽然大大提升了数据的写入能力,却是以牺牲部分读取性能为代价的,故此这种结构通常适合于写多读少的场景,这是HBase写比读速度快的根本原因所在。
五 HRegionServer的工作机制
5.1 HRegion分配机制
一个 HRegion 只能分配给一个 HRegionServer,也就是说HRegionServer和HRegion的关系是一对多的关系。master 记录了HBase集群中哪些 HRegionServer 是可用的。以及哪些 HRegion 已经分配给了哪些 HRegionServer,哪些 HRegion 还没有分配。
当HRegionServer需要分配的新的 HRegion时,Master 就会给这个 HRegionServer 发送一个装载请求,把 HRegion 分配给这个 HRegionServer。HRegionServer 得到请求后,就开始对此 HRegion 提供服务。
5.2 HRegionServer上线
Master使用Zookeeper来跟踪HRegionServer的状态。当某个HRegionServer启动时,首先在Zookeeper上的/hbase/rs目录下建立代表自己的znode。由于Master订阅了/hbase/rs目录上的变更消息,当/hbase/rs目录下的文件出现新增或删除操作时,Master可以得到来自Zookeeper的实时通知。因此一旦HRegionServer上线,Master能马上得到消息。
5.3 HRegionServer下线
当RegionServer下线时,它和Zookeeper的会话就会断开。当Master连续几次和RegionServer都无法通信时,就可以确定HRegionServer和Zookeeper之间的网络断开了,或者是这个RegionServer挂了。
六 性能调优问题
6.1 合理设计HBase表的RowKey
我们知道,在HBase中,是通过4个维度一起来定位一条数据:行键(RowKey)、列族(Column Family)、列限定符(Column Qualifier)、时间戳(Timestamp)。其中RowKey是最容易出问题的:
① 首先是单点集中问题,我所见过的单点集中问题主要有下面几种情况:
RowKey前面的字符比较集中固定。集群节点过少。
集群节点少是硬件不足的表现,我们主要考虑RowKey的设计问题。我们建议RowKey的设计方式如下:
随机字符(2位) + 时间位(14位)+ 业务编码(4位)
亲身检测过:前后两种方案对比,前者的MR程序跑了2个小时,后者只花了10分钟。
② RowKey的长度过于太长
在HBase中,RowKey、列族、列名等都是以byte[]的形式传输的。RowKey的上限长度是64KB,但是我们使用HBase主要是为了让它快,因此在实际的应用中,RowKey的大小不会超过100B。这主要是从下面两个方面考虑的。
HBase的数据是存储在HFile中的,RowKey是KeyValue结构中的一个域。假设RowKey的大小是100B,那么1000万条数据,RowKey可能就占用了1GB的空间,也会影响HBase的响应速度的。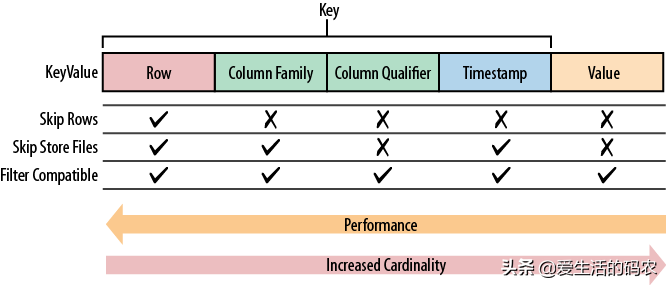
RowKey的设计原则
HBase中的MemStore和BlockCache,分别对应列族在Store级别的写入缓存和RegionServer级别的读取缓存。如果RowKey过长,缓存中存储数据的密度就会降低,影响数据落地或查询效率。
目前服务器一般都安装64位操作系统,内存按照8B对齐,因此,在设计RowKey时候,一般考虑做成8B的整数倍,例如如16B或者24B。同理,列族、列名的命名在保证可读的情况下尽量短。HBase官方不推荐使用3个以上列族,因此实际上列族命名几乎都用一个字母,比如‘c’或‘f’。
6.2 使用压缩技术
HBase支持很多压缩算法,而且能够做到从列簇级别上进行压缩。压缩可以减少网络带宽,同时也能够加快数据的读取,因此使用压缩算法通常能带来可观的性价比。
HBase支持的压缩算法
注意:如果一张表已经使用了某种压缩算法,那么现在想更改这张表的压缩格式,要先将该表disable才能修改,之后再enable重新上线。



