
在计算机的世界里,只有二进制的0和1,如何表示和显示字符呢?
表示字符毫无疑问就是通过编码来进行数字化、二进制化。如ASCII编码方案就是用65来表示字母A。
如何显示字符A呢?可以用点阵图来显示,当然也可以用函数定义的矢量图来显示。
不同的编码方案会对应不同的字符集。
使用一个字节来编码,足够表示全部的英文字符、数字和常用的标点符号,如ASCII编码。
使用较多的字节来编码,所能表示的字符的数量自然就多,当使用多字节(例如4个字节)来编码时,那些排在编码序列前面的字符其实并不需要4个字节来存储,前面的一个字节就行了,然后是两个字节、三个字节,只有排在序列最后的才需要使用4个字节,所以,相同的编码方案可以使用不同的存储方案,这就是Unicode编码与utf(Unicode Transformation Format)的关系,前者是编码方案,后者是Unicode编码方案的存储方案(存储实现)。
Unicode是由国际组织设计,可以容纳全世界所有语言文字。Unicode的学名 是”Universal Multiple-Octet Coded Character Set”,简称为UCS。UCS可以看作是”Unicode Character Set”的缩写。
big endian(大端)和little endian(小端)是CPU处理多字节数的不同方式,各自有不同的优缺点。例如“汉”字的Unicode编码是6C49。那么写到文件里时,究竟是将6C写在前面,还是将49写在前 面?如果将6C写在前面,就是big endian。如果将49写在前面,就是little endian。
intel x86系列CPU都是小端模式,省内存(因为有些处在序列的前面编码用多字节存储时,高端字节都是0),方便类型转换时的截断操作(内存地址无须改变)。Motorola680x的CPU使用大端对齐,java虚拟机里面的字节序是大端,网络字节序也是大端。
操作系统、需要处理文字的应用程序、文件等都需要考虑一个字符编码及字符集选择的问题。
1 操作系统代码页与locale设置
目前Windows的内核已经支持Unicode字符集,这样在内核上可以支持全世界所有的语言文字。但是由于现有的大量程序和文档都采用了某种特定语言的编码,例如GBK,Windows不可能不支持现有的编码,而全部改用Unicode。
Windows使用代码页(code page)来适应各个国家和地区。code page可以被理解为内码。GBK对应的code page是CP936。
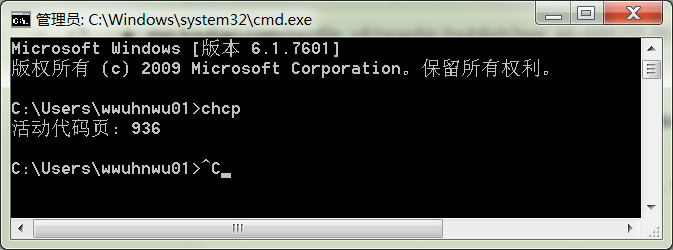
如果操作系统的系统区域 locale 设置为简体中文,那么两个连续的扩展 ASCII 码就会根据 GB2312 编码解析。
#include <iostream>using namespace std;int main(){ char* pStr="我aa"; // 一个中文字符,一个英文字母,一个全角字母 cout<<sizeof("我aa")<<endl; cout<<hex<<pStr[0]-0; // 中文字符“我”的GB2312的编码是ced2 cout<<pStr[1]-0<<endl; char cn[3] = "我"; cout<<cn<<endl; while(1); return 0;}
打印结果如下:
6ffffffceffffffd2我
GB2312中”我”的编码正是ced2,另外,GB2312兼容ASCII。
以上虽然能够整体处理GB2312,但颗粒化细分到字符时,处理起来就有些问题了,此时就需要明确统一用unicode编码来处理:
string str="中国人china"; cout<< str.length() <<endl; // 11,每个字符使用不同的位长(1个或多个字节) wstring wstr=L"中国人china"; cout<< wstr.length() <<endl; // 8,每个字符使用相同的位长(2个字节)
C95标准化了两种表示大型字符集的方法:宽字符(wide character,该字符集内每个字符使用相同的位长)以及多字节字符(multibyte character,每个字符可以是一到多个字节不等,而某个字节序列的字符值由字符串或流(stream)所在的环境背景决定)。
多字节字符和宽字符(也就是wchar_t)的主要差异在于宽字符占用的字节数目都一样,而多字节字符的字节数目不等,这样的表示方式使得多字节字符串比宽字符串更难处理。比方说,即使字符’A’可以用一个字节来表示,但是要在多字节的字符串中找到此字符,就不能使用简单的字节比对,因为即使在某个位置找到相符合的字节,此字节也不见得是一个字符,它可能是另一个不同字符的一部分。
如果程序中没有用setlocale函数设置地域等其他参数,那么程序运行时locale 被初始化为默认的 C locale,其采用的字符编码是所有本地 ANSI 字符集编码的公共部分,是用来书写C语言源程序的最小字符集。
#include <stdio.h>#include <locale.h>#include <tchar.h> // _T()#include <wchar.h>int main(){ wchar_t wcs[3] = L"中文"; char *p1,*p2; // 设置地域设置或获取地域设置信息 p1 = setlocale(LC_ALL, NULL); p2 = setlocale(LC_ALL, ""); // ""表示默认的本地环境,如"chs" wprintf(L"%lsn", wcs); printf("地域设置:%sn", p1); printf("地域设置:%sn", p2); while(1); return 0;}/*中文地域设置:C地域设置:Chinese (Simplified)_People's Republic of China.936*/
2 文本文件的编码方案及存储
使用Windows记事本的“另存为”,可以在GBK、Unicode、Unicode big endian和UTF-8这几种编码方式间相互转换。
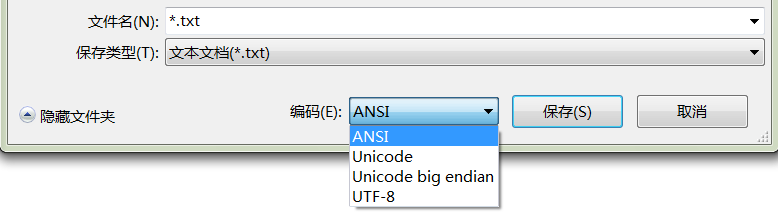
同样是txt文件,Windows是怎样识别编码方式的呢?
当一个软件打开一个文本时,它要做的第一件事是决定这个文本究竟是使用哪种字符集的哪种编码保存的。软件有三种途径来决定文本的字符集和编码: 最标准的途径是在文件的开头写入元数据(数据的数据),如下表:
开头字节 Charset/encoding
EF BB BF UTF-8 FE FF UTF-16/UCS-2, little endian
FF FE UTF-16/UCS-2, big endian
FF FE 00 00 UTF-32/UCS-4, little endian.
00 00 FE FF UTF-32/UCS-4, big-endian.
UTF-8以字节为编码单元,没有字节序的问题。UTF-16以两个字节为编码单元,在解释一个UTF-16文本前,首先要弄清楚每个编码单元的字节序。例如“奎”的Unicode编码是594E,“乙”的Unicode编码是4E59。如果我们收到UTF-16字节流“594E”,那么这是“奎” 还是“乙”?
Unicode规范中推荐的标记字节顺序的方法是BOM。BOM不是“Bill Of Material”的BOM表,而是Byte Order Mark。BOM是一个有点小聪明的想法:
在UCS编码中有一个叫做”ZERO WIDTH NO-BREAK SPACE”的字符,它的编码是FEFF。而FFFE在UCS中是不存在的字符,所以不应该出现在实际传输中。UCS规范建议我们在传输字节流前,先传输 字符”ZERO WIDTH NO-BREAK SPACE”。
这样如果接收者收到FEFF,就表明这个字节流是Big-Endian的;如果收到FFFE,就表明这个字节流是Little-Endian的。因 此字符”ZERO WIDTH NO-BREAK SPACE”又被称作BOM。
例如在bat中使用重定向来生成文本文件时,第一行便可以声明chcp,如:
chcp 65001echo ^<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" >more.htmlecho "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"^> >>more.htmlecho ^<html xmlns="http://www.w3.org/1999/xhtml"^> >>more.htmlecho ^<base target="_blank" /^> >>more.htmlecho ^<meta content="text/html; charset=utf-8" /^> >>more.htmlecho ^<head^> >>more.htmlecho ^<title^>contents^</title^> >>more.html
生成的more.html文件对应的存储方案就是chcp 65001对应的存储方案,也就是utf-8。
3 编程中编译环境的字符集设置及字符类型及库函数
对于强类型语言来说,不同的字符集对应的是不同的字符类型,常量需要不同的标示,库函数都会提供不同的版本。
3.1 编译环境的字符集设置
VC6默认使用的配置是多字节(_MBCS),也就是非Unicode的,VC2010默认使用的配置是Unicode。
不同的字符集设置使用不同的类型与库函数
// ANSI:char buffer[8];sprintf(buffer,"Time%d",123);// Unicodewchar buffer[8];swprintf(buffer,L"Time%d",123);
以下用一个VC6.0设定UNICODE编译环境的实例来说明其中的一些细节:
I 安装完成后:需要把VC98MFCLIB下的MFC42U.LIB和MFC42UD.LIB手动拷贝到对应的安装目录下.
II 为工程添加UNICODE和_UNICODE预处理选项:打开[工程]→[设置…]对话框,在C/C++标签对话框的“预处理程序定义”中去除_MBCS(Multiple Bits Character Set),加上_UNICODE,UNICODE。(注意中间用逗号隔开).在没有定义UNICODE和_UNICODE前,所有函数和类型都默认使用ANSI的版本;在定义了UNICODE和_UNICODE之后,所有的MFC类和Windows API都变成了宽字节版本了。
III 设置程序入口点:因为MFC应用程序有针对Unicode专用的程序入口点,我们要设置entry point。否则就会出现连接错误。设置entry point的方法是:打开[工程]→[设置…]对话框,在Link页的Output类别的Entry Point里填上wWinMainCRTStartup。
IV 使用ANSI/Unicode通用数据类型:微软提供了一些ANSI和Unicode兼容的通用数据类型或宏,如_T 、TCHAR、LPTSTR、LPCTSTR。顺便说一下,LPCTSTR和const TCHAR*是完全等同的。其中L表示long指针,这是为了兼容Windows 3.1等16位操作系统遗留下来的,在Win32 中以及其它的32位操作系统中,long指针和near指针及far修饰符都是为了兼容的作用,没有实际意义。P(pointer)表示这是一个指针;C(const)表示是一个常量;T(_T宏)表示兼容ANSI和Unicode,STR(string)表示这个变量是一个字符串。
综上可以看出, LPCTSTR表示一个指向常固定地址的可以根据一些宏定义改变语义的字符串。比如:
TCHAR* szText=_T(“Hello!”);TCHAR szText[]=_T(“I Love You”);LPCTSTR lpszText=_T(“大家好!”);
使用函数中的参数最好也要有变化,比如:MessageBox(_T(“你好”));
其实,在上面的语句中,即使您不加_T宏,MessageBox函数也会自动把“你好”字符串进行强制转换。但我还是推荐您使用_T宏,以表示您有Unicode编码意识。
3.2 字符类型
3.2.1 char
char关键字指定一个8位的数据项。
The char keyword specifies an eight-bit data item.
默认情况下char等同于unsigned char。
对ANSI字符集(_MBCS)对应的就是char类型。
3.2.2 wchar_t
wchar_t是一个宽的类型。
The wchar_t keyword designates a wide_character type.
还可以在MSDN关于wchar_t的Remarks中看到:
① wchar_t类型被MIDL定义成一个16位的无符号型的short。
② wchar_t允许重新定义,只要和之前的定义保持一致,也可以使用const的声明。
③ 在wchar_t前使用L字符或用一个string常量来指定wchar_t常量。
对于Unicode的字符集对应wchar_t类型。
wchar_t中的字符t可以理解为typedef。
3.2.3 TCHAR
对于windows程序,TCHAR 是一个映射宏,当定义 UNICODE 时,该数据类型映射到 wchar_t,如果没有定义 UNICODE,那么它映射到 char。
如果你的程序定义为UNICODE的,那么TCHAR定义为wchar_t(16位的字符类型);否则,TCHAR定义为char(8位的字符类型)。
TCHAR中的字符T可以理解为TEXT(见下面3.3关于字符串常量的定义)。
3.2.4 string
这个类型为类型char类型定义了一个特定的类模板string,属于STL中的模板类库。
typedef basic_string string;
The type describes a specialization of template class basic_string for elements of type char.
3.2.5 CString
CString是MFC中的模板类库。
① CString没有基类;
② 一个CString对象由可变长度的有序的字符组成;
③ CString是基于TCHAR的数据类型,如果你的程序定义为UNICODE的,那么TCHAR定义为wchar_t,wchar_t为(16位的字符类型);否则,TCHAR定义为char(8位的字符类型)。在Unicode下,CString对象由16位的字符组成。不在Uniconde情况下,CString由8位长的字符组成。
3.2.6 windows32中一些特殊的字符串指针定义
PWSTR 指向Unicode字符串的指针。
PCWSTR 指向一个恒定的Unicode字符串的指针。
对应的ANSI数据类型为CHAR,LPSTR和LPCSTR。
ANSI/Unicode通用数据类型为TCHAR,PTSTR,LPCTSTR。
LPSTR = char * LPCSTR = const char * LPWSTR = wchar_t * LPCWSTR = const wchar_t * LPOLESTR = OLECHAR * = BSTR = LPWSTR(Win32) LPCOLESTR = const OLECHAR * = LPCWSTR(Win32) LPTSTR = _TCHAR * LPCTSTR = const _TCHAR *
3.3 常量表示字符串
前面加L表示该字符串是Unicode字符串。
_T是一个宏,如果项目使用了Unicode字符集(定义了UNICODE宏),则自动在字符串前面加上L,否则字符串不变。因此,Visual C++里面,定义字符串的时候,用_T来保证兼容性。VC支持ascii和unicode两种字符类型,用_T可以保证从ascii编码类型转换到unicode编码类型的时候,程序不需要修改。
ANSI字符串字面量的写法: “abc string”Unicode字符串字面量的写法: L“abc string”ANSI/Unicode字符串字面量的写法: T(“abc string”)或_TEXT(“abc string”)
如下面三行语句:
TCHAR szStr1[] = TEXT("str1");char szStr2[] = "str2";WCHAR szStr3[] = L("str3");
TEXT、_TEXT 和_T 一样的。
那么第一行语句在定义了UNICODE时会解释为第三行语句,没有定义时就等于第二行语句。
但第二行语句无论是否定义了UNICODE都是生成一个ANSI字符串,而第三行语句总是生成UNICODE字符串。
为了程序的可移植性,建议都用第一种表示方法。但在某些情况下,某个字符必须为ANSI或UNICODE,那就用后两种方法。
3.4 库函数
ANSI 操作函数以str开头,如strcpy(),strcat(),strlen();
Unicode操作函数以wcs开头,如wcscpy,wcscpy (),wcslen();
MBCS 操作函数以_mbs开头 _mbscpy
ANSI/Unicode 操作函数以_tcs开头 _tcscpy(C运行期库)
ANSI/Unicode 操作函数以lstr开头 lstrcpy(Windows函数)
所有新的和未过时的函数在Windows中都同时拥有ANSI和Unicode两个版本。ANSI版本函数结尾以A表示;Unicode版本函数结尾以W表示。
Microsoft公司为Unicode设计了WindowsAPI,这样,可以尽量减少代码的影响。实际上,可以编写单个源代码文件,以便使用或者不使用Unicode来对它进行编译。只需要定义两个宏(UNICODE和_UNICODE),就可以修改然后重新编译该源文件。
_UNICODE宏用于C运行期头文件,而UNICODE宏则用于Windows头文件。当编译源代码模块时,通常必须同时定义这两个宏。
#ifdef UNICODE#define CreateWindowEx CreateWindowExW#else#define CreateWindowEx CreateWindowExA#endif // !UNICODE
3.5 类型转换(windows程序)
Unicode转换为ANSI使用:MultiByteToWideChar()。
ANSI转换为Unicode使用:WideCharToMultiByte()。
void CString2Char(CString str, char ch[]) { int i; char *tmpch; int wLen = WideCharToMultiByte(CP_ACP, 0, str, -1, NULL, 0, NULL, NULL);//得到Char的长度 tmpch = new char[wLen + 1]; //分配变量的地址大小 WideCharToMultiByte(CP_ACP, 0, str, -1, tmpch, wLen, NULL, NULL); //将CString转换成char* for(i = 0; tmpch[i] != '/0'; i++) ch[i] = tmpch[i]; ch[i] = '/0'; }
3.6 如何编写符合ANSI和Unicode的应用程序?
a 在编程的时候使用TCHAR数据类型,此类型能够根据预编译宏的定义,将其转换为ANSI或者是Unicode。
b 将显式数据类型(如BYTE和PBYTE)用于字节、字节指针和数据缓存。
c 将TEXT宏用于原义字符和字符串。
d 预编译宏_MBCS、_UNICODE和UNICODE。_MBCS是多字节和ANSI字符串的编译宏。此时TCHAR将转换为char。_UNICODE和UNICODE是Unicode编码的预编译宏,TCHAR将转换为wchar_t。_UNICODE和UNICODE与_MBCS不能在编译的时候同时被定义。_UNICODE宏用于C运行期库的头文件,UNICODE宏用于Windows头文件。一般同时定义这两个宏。
e 修改字符串运算问题。例如函数通常希望在字符中传递一个缓存的大小,而不是字节。这意味着不应该传递sizeof(szBuffer),而应该传递(sizeof(szBuffer)/sizeof(TCHAR)。另外,如果需要为字符串分配一个内存块,并且拥有该字符串中的字符数目,那么请记住要按字节来分配内存。这就是说,应该调用malloc(nCharacters *sizeof(TCHAR)),而不是调用malloc(nCharacters)。
4 读写确定编码的文件
看下面的实例:
void test(){ CFile myFile; if ( myFile.Open( _T("c:\myfile.txt"), CFile::modeCreate | CFile::modeReadWrite ) ) { CString str=TEXT("a我"); //myFile.Write("xffxfe",2); myFile.Write( str, str.GetLength()*sizeof(TCHAR) ); myFile.Flush(); }}
运行程序,然后用写字板、记事本、NotePad++、UE(UEdit)分别打开mfile.txt发现,有的能正常显示,有的则乱码。要知道,你往myfile.txt写进去的是 两个字符的Unicode编码,用某文本程序去打开myfile.txt,倘若该程序默认情况下读取文本时是按Unicode来解析的,则不会乱码,否则就乱码。我们把注释的那行代码的注释拿掉,用任何支持Unicode的文本程序去打开myfile.txt就不会出错了,因为一个文本中的前两个字节FF FE便向试图打开该文本的程序表明该文本应该用Unicode进行解析(你可以用NotePad++新建几个Unicode格式的文本,随便保存几个字符,然后用UE以16进制格式查看便可知Unicode文本的前两个字节都是FF FE)。
CString如何转换为char*?问这个问题之前,最好问下自己:我的目的是什么,为何要进行这样的转换,当前项目有没有设置Unicode。要知道,如果设置了Unicode,则CString存储的是Unicode字符串,转换为char*后,你如果直接显示这个char*或者写到文件中(没有把FF FE写到文件开始处)然后打开,则会(假如打开文件的程序默认不以Unicode进行解析)出现乱码,所以,这种情况下,转换为char*的意义不大——这不是说不能把Unicode串转为char*,这完全是可行的,本质上这只是在把一个Unicode字符串的内存内容”活生生”取出来而已。不管怎样,下面的代码重新修改了OnInitDialog函数,演示了几种情况:
void test(){ CFile myFileW,myFileA,myFileCharArrow,myFileWOrA; if ( myFileW.Open( _T("c:\myfileW.txt"), CFile::modeCreate | CFile::modeReadWrite ) && myFileA.Open( _T("c:\myfileA.txt"), CFile::modeCreate | CFile::modeReadWrite ) && myFileCharArrow.Open( _T("c:\myfileCharArrow.txt"), CFile::modeCreate | CFile::modeReadWrite ) && myFileWOrA.Open( _T("c:\myFileWOrA.txt"), CFile::modeCreate | CFile::modeReadWrite )) { CString strW=TEXT("a我");//本项目设置了Unicode字符集,CString会被替换为CStringW CStringA strA(strW); myFileW.Write( strW, strW.GetLength()*2); myFileW.Flush(); myFileA.Write(strA,strA.GetLength()); myFileA.Flush(); //CString的GetString返回的const类型指针,要么在右边强转,要么左边用const类型的char*去接 //注意指针命名:p是pointer,c是const,如果有t则是TEXT,w是wide,l是long char* pstr=(char*)strA.GetString(); /* 下面这行代码若不注掉,会报错,因为本程序是Unicode程序, * strW会是一个CStringW类型的字符串,它的GetString返回的是LPCWSTR类型指针 * 当然不能赋值给LPCSTR类型指针了,一个是const wchar_t*,另一个是const char* */ //const char* pcstr1=strW.GetString(); myFileCharArrow.Write(pstr,strlen(pstr)); myFileCharArrow.Flush(); // 假设我们在编程中,不知道有没有使用Unicode设置,为了通用, // 我们可以尽量使用宏及通用版本的相关函数(如_tcslen) CString strWOrA=TEXT("a我"); //注意这里的TCHAR不一定就是wchar_t,这取决于程序是否设置了Unicode const TCHAR* pctstr=strWOrA.GetString();//CString的GetString返回的是const指针 myFileWOrA.Write(ptstr,_tcslen(pctstr)*sizeof(TCHAR)); myFileWOrA.Flush(); }}
其中,CED2是”我“的GB2312编码,6211(注意字节高低次序)是”我“的Unicode编码,我们可知,CStringA strA(strW)这行代码,一定进行了码表间的转换。
GB2312编码查询:
https://wwuhn.github.io/witisoPC/21/code/GB2312简体中文编码表.html
Unicode编码查询:
https://wwuhn.github.io/witisoPC/21/code/Unicode汉字编码表(中日韩).html
实例2:将文本框内容写入一个utf-8的html文件:
//string path = (const_cast<CString>eNovel).GetBuffer(0); CString path = eNovel; CString dir,fn; GetDlgItem(IDC_title2)->GetWindowText(dir); GetDlgItem(IDC_new2)->GetWindowText(fn); CString contents; GetDlgItem(IDC_textbox)->GetWindowText(contents); path += dir+"\"; string fname = path.GetBuffer(0); fname += fn.GetBuffer(0); fname += ".html"; ofstream ofs(fname.c_str(),fstream::out); //可以新建文件,但不能新建路径 if(!ofs) { string str = fname+"文件没有正常打开"; GetDlgItem(IDC_status)->SetWindowText(str.c_str()); return; } string strLine; // 写入文件框内容,需要UTF-8的格式写入,否则是乱码 wchar_t* wszString = contents.AllocSysString(); // unicode to UTF8 //预转换,得到所需空间的大小 int u8Len = ::WideCharToMultiByte(CP_UTF8, NULL, wszString, wcslen(wszString), NULL, 0, NULL, NULL); //同上,分配空间要给''留个空间 //UTF8虽然是Unicode的压缩形式,但也是多字节字符串,所以可以以char的形式保存 char* szU8 = new char[u8Len + 1]; //转换 //unicode版对应的strlen是wcslen ::WideCharToMultiByte(CP_UTF8, NULL, wszString, wcslen(wszString), szU8, u8Len, NULL, NULL); //最后加上'' szU8[u8Len] = ''; //MessageBox不支持UTF8 //写文本文件,UTF8-BOM的标识符是0xbfbbef //文件开头 //cFile.SeekToBegin(); ofs.seekp(0,ios::beg); //写BOM,低位写在前 //cFile.Write("xefxbbxbf", 3); ofs<<"xefxbbxbf"; //写入内容 //cFile.SeekToEnd(); //ofs.seekp(0,ios::end); ofs.seekp(ios::end); //mFile.Write(sUNICODE,sizeof(sUNICODE)); //将文件变为UNICODE编码 //cFile.Write(szU8, u8Len * sizeof(char)); ofs<<szU8; ofs.flush(); delete[] szU8; szU8 =NULL;


