1. 前言
Gartner预测到2023年,全球3/4的数据库都会跑在云上,云原生数据库最大的优势之一便是天然拥有云计算的弹性能力,数据库可以像水、电、煤一样随取随用,而Autosaling能力便是弹性的极致体现。数据库的Autoscaling能力是指数据库处于业务高峰期时,自动扩容增加实例资源;在业务负载回落时,自动释放资源以降低成本。
业界的云厂商AWS与Azure在其部分云数据库上实现了Autoscaling能力,阿里云数据库同样实现了其特有的Autosaling能力,该能力由数据库内核、管控及DAS(数据库自治服务)团队共同构建,内核及管控团队提供了数据库Autoscaling的基础能力,DAS则负责性能数据的监测、Scaling决策算法的实现及Scaling结果的呈现。DAS(Database Autonomy Service)是一种基于机器学习和专家经验实现数据库自感知、自修复、自优化、自运维及自安全的云服务,帮助用户消除数据库管理的复杂性及人工操作引发的服务故障,有效保障数据库服务的稳定、安全及高效。其解决方案架构如图1.所示,Autoscaling/Serverless能力在其中属于“自运维”的部分。
图1. DAS的解决方案架构
2. Autosaling的工作流程
数据库Autoscaling整体的工作流程可定义为如图2.所示的三个阶段,即“When:何时触发Scaling”、“How:采取哪种方式Scaling”及“What:Scaling到哪个规格”。
何时触发Scaling即确定数据库实例的扩容与回缩的时机,通常的做法是通过观测数据库实例的性能指标,在实例的负载高峰期执行扩容操作、在负载回落时执行回缩操作,这是常见的Reative被动式触发方式,除此之外我们还实现了基于预测的Proactive主动式触发方式。关于触发时机在2.1章节会进行详细的介绍。Scaling的方式通常有ScaleOut(水平扩缩容)与ScaleUp(垂直扩缩容)两种形式。以分布式数据库PolarDB为例,ScaleOut的实现形式是增加只读节点的数量,例如由2个只读节点增加至4个只读节点,该方式主要适用于实例负载以读流量占主导的情形;ScaleUp的实现形式是升级实例的CPU与内存规格,如由2核4GB升级至8核16GB,该方式主要适用于实例负载以写流量占主导的情形。关于Scaling方式在2.2章节会进行详细的介绍。在扩容方式确定后需要选择合适的规格,来使实例的负载降至合理的水位。例如对于ScaleOut方式,需要确定增加多少个实例节点;对于ScaleUp方式,需要确定升级实例的CPU核数与内存,以确定升级至哪种实例规格。关于扩容规格的选择在2.3章节会进行详细的介绍。

图2. Autoscaling的工作流程图示
2.1 Autoscaling的触发时机
2.1.1 Reactive被动式触发(基于观察)
基于观察的Reactive被动式触发是当前Autoscaling主要的实现形式,由用户为不同的实例设置不同的扩、缩容触发条件。对于计算性能扩容,用户可以通过设置触发CPU阈值、观测窗口长度、规格上限、只读节点数量上限及静默期等选项来配置符合业务负载的触发条件;对于存储空间扩容,用户可以通过设置空间的扩容触发阈值及扩容上限来满足实例业务的增长,并避免磁盘资源的浪费。被动式触发的配置选项在3.2章节会进行详细的展示。
Reactive被动式触发的优点是实现相对容易、用户接受度高,但如图3.所示,被动式触发也存在其缺点,通常Scaling操作在达到用户配置的观测条件后才会真正执行,而Scaling操作的执行也需要一定的时间,在这段时间内用户的实例可能已经处于高负载较长时间,这会在一定程度上影响用户业务的稳定性。
图3. 被动式触发的扩容资源对比图示
2.1.2 Proactive主动式触发(基于预测)
解决Reactive被动式触发的方法便是Proactive主动式触发,如图4.所示,通过对实例负载的预测,在预测实例负载即将处于高峰前的一段时间,便提前对实例执行扩容操作,使实例能够平稳度过整个业务高峰期。周期性workload是基于预测的方式中最典型的应用场景(线上具有周期性特征的实例约占40%),DAS使用了达摩院智能数据库实验室同学实现的周期性检测算法,该算法结合了频域和时域信息,准确率达到了80%以上。例如对具有“天级别”周期性特征的线上实例,Autoscaling服务会在实例每天的业务高峰期开始之前进行扩容,以使实例更好地应对周期性的业务峰值。
图4. 主动式触发的扩容资源对比图示
我们同样在RDS-MySQL的存储空间扩容里实现了基于预测的方式,基于实例过去一段时间的磁盘使用量指标,使用机器学习算法预测出实例在接下来的一段时间内存储空间会达到的最大值,并会根据该预测值进行扩容容量的选择,可以避免实例空间快速增长带来的影响。


图5. 基于磁盘使用量趋势的预测
2.2 Autoscaling的方式决策
DAS的Autoscaling方式有ScaleOut与ScaleUp两种,在给出Scaling方案的同时也会结合Workload全局决策分析模块给出更多的诊断建议(如SQL自动限流、SQL索引建议等等)。如图6.所示是Scaling方式的决策示意图,该示意图以PolarDB数据库作为示例。PolarDB数据库采用的是计算存储分离的一写多读的分布式集群架构,一个集群包含一个主节点和多个只读节点,主节点处理读写请求,只读节点仅处理读请求。图6.所示的“性能数据监测模块”会不断的监测集群的各项性能指标,并判断当前时刻的实例负载是否满足2.1章节所述的Autoscaling触发条件,当满足触发条件时,会进入到图6.中的Workload分析模块,该模块会对实例当前的Workload进行分析,通过实例的会话数量、QPS、CPU使用率、锁等指标来判断实例处于高负载的原因,若判断实例是由于死锁、大量慢SQL或大事务等原因导致的高负载,则在推荐Autoscaling建议的同时也会推出SQL限流或SQL优化建议,使实例迅速故障自愈以降低风险。
在Autoscaling方式的决策生成模块,会判断采取何种Scaling方式更有效。以PolarDB数据库为例,该模块会通过实例的性能指标以及实例的主库保护、事务拆分、系统语句、聚合函数或自定义集群等特征来判断集群当前的负载分布,若判断实例当前以读流量占主导,则会执行ScaleOut操作增加集群的只读节点数量;若判断实例当前以写流量占主导,则会执行ScaleUp操作来升级集群的规格。ScaleOut与ScaleUp决策的选择是一个很复杂的问题,除了考虑实例当前的负载分布外,还需要考虑到用户设置的扩容规格上限及只读节点数量上限,为此我们也引入了一个效果追踪与决策反馈模块,在每次决策判断时,会分析该实例历史上的扩容方式及扩容效果,以此来对当前的Scaling方式选择算法进行一定的调整。
图6. PolarDB的Scaling方式决策示意图
2.3 Autoscaling的规格选择
2.3.1 ScaleUp决策算法
ScaleUp决策算法是指当确定对数据库实例执行ScaleUp操作时,根据实例的workload负载及实例元数据等信息,为当前实例选择合适的规格参数,以使实例当前的workload达到给定的约束。最开始DAS Autoscaling的ScaleUp决策算法基于规则实现,以PolarDB数据库为例,PolarDB集群当前有8种实例规格,采用基于规则的决策算法在前期足够用;但同时我们也探索了基于机器学习/深度学习的分类模型,因为随着数据库技术最终迭代至Serverless状态,数据库的可用规格数量会非常庞大,分类算法在这种场景下会有很大的用武之地。如图7.及图8.所示,我们当前实现了基于性能数据的数据库规格离线训练模型及实时推荐模型,通过对自定义CPU使用率的范围标注,参考DAS之前落地的AutoTune自动调参算法,在标注数据集进行模型分类,并通过实现的proxy流量转发工具进行验证,当前的分类算法已经取得了超过80%的准确率。
图7. 基于性能数据的数据库规格ScaleUp模型离线训练示意图
图8. 基于性能数据的数据库规格ScaleUp实时推荐方法示意图
2.3.2 ScaleOut决策算法
ScaleOut决策算法与ScaleUp决策算法的思路类似,本质问题是确定增加多少个只读节点,能使实例当前的workload负载降至合理的水位。在ScaleOut决策算法里,我们同样实现了基于规则的与基于分类的算法,分类算法的思想与2.3.1章节里描述的基本类似,基于规则的算法思想则如图9.所示,首先我们需要确定与读流量最相关的指标,这里选取的是com_select、qps及rows_read指标,s_i表示第i个节点读相关指标的表征值,c_i表示第i个节点的目标约束表征值(通常使用CPU使用率、RT等直接反应业务性能的指标),f指目标函数,算法的目标便是确定增加多少个只读节点X,能使整个集群的负载降至f函数确定的范围。该计算方法明确且有效,算法上线后,以变配后集群的CPU负载是否降至合理水位作为评估条件,算法的准确率达到了85%以上,在确定采取ScaleOut变配方式后,ScaleOut决策算法新增的只读节点基本都能处于“恰好饱和”的工作负载,能够有效的提升数据库实例的吞吐。
图9. 基于性能数据的数据库节点数量ScaleOut推荐算法示意图
3. 落地
3.1 实现架构
Autoscaling能力集成在DAS服务里,整个服务涉及异常检测、全局决策、Autoscaling服务、底层管控执行多个模块,如图10.所示是DAS Autoscaling的服务能力架构。异常检测模块是DAS所有诊断优化服务(Autoscaling、SQL限流、SQL优化、空间优化等)的入口,该模块会7*24小时对监控指标、SQL、锁、日志及运维事件等进行实时检测,并会基于AI的算法对其中的趋势如Spike、Seasonaliy、Trend及Meanshift等进行预测及分析;DAS的全局决策模块会根据实例当前的workload负载给出最佳的诊断建议;当由全局决策模块确定执行Autoscaling操作时,则会进入到第2章节介绍的Autoscaling工作流程,最终通过数据库底层的管控服务来实现实例的扩、缩容。
图10. DAS及AutoScaling的服务能力架构
3.2 产品方案
本章节将介绍Autoscaling功能在DAS里的开启方式。如图11.所示是DAS的阿里云官网产品首页,在该界面可以看到DAS提供的所有功能,如“实例监控”、“请求分析”、“智能压测”等等,点击“实例监控”选项可以查看用户接入的所有数据库实例。我们点击具体的实例id链接并选择“自治中心”选项,可以看到如图12.及图13.所示的PolarDB自动扩、缩容设置及RDS-MySQL自动扩容设置,对于PolarDB实例,用户可以设置扩容规格上限、只读节点数量上限、观测窗口及静默期等选项,对于RDS-MySQL实例,用户可以设置触发阈值、规格上限及存储容量上限等选项。
图11. DAS产品首页
图12. PolarDB自动扩、缩容设置图示
图13. RDS-MySQL自动扩、缩容设置图示
3.3 效果案例
本章节将介绍两个具体的线上案例。如图14.所示为线上PolarDB实例的计算规格Autoscaling触发示意图,在05:00-07:00的时间段,实例的负载慢慢上升,最终CPU使用率超过了80%,在07:00时触发了自动扩容操作,后台的Autoscaling服务判断实例当前读流量占主导,于是执行了ScaleOut操作,为集群增加了两个只读节点,通过图示可以看到,增加节点后集群的负载明显下降,CPU使用率降至了50%左右;在之后的2个小时里,实例的业务流量继续增加,导致实例负载继续在缓慢上升,于是在09:00的时候再次达到了扩容的触发条件,此时后台服务判断实例当前写流量占主导,于是执行了ScaleUp操作,将集群的规格由4核8GB升级到8核16GB,由图示可以看到规格升级后实例的负载趋于稳定,并维持了近17个小时,之后实例的负载下降并触发了自动回缩操作,后台Autoscaling服务将实例的规格由8核16GB降至4核8GB,并减少了两个只读节点。Autoscaing服务在后台会自动运行,无需人工干预,在负载高峰期扩容、在负载低谷时回缩,提升业务稳定性的同时降低了用户的成本。
图14. 线上PolarDB 水平扩容、垂直扩容效果示意图
如图15.所示为线上RDS-MySQL实例的存储空间自动扩容示意图,左侧图表示实例在近3个小时内触发了3次磁盘空间扩容操作、累计扩容近300GB,右侧是磁盘空间的增长示意图,可以发现在实例存储空间迅速增长时,空间自动扩容操作能够无缝执行,真正做到了随用随取,在避免实例空间打满的同时节省了用户的成本。
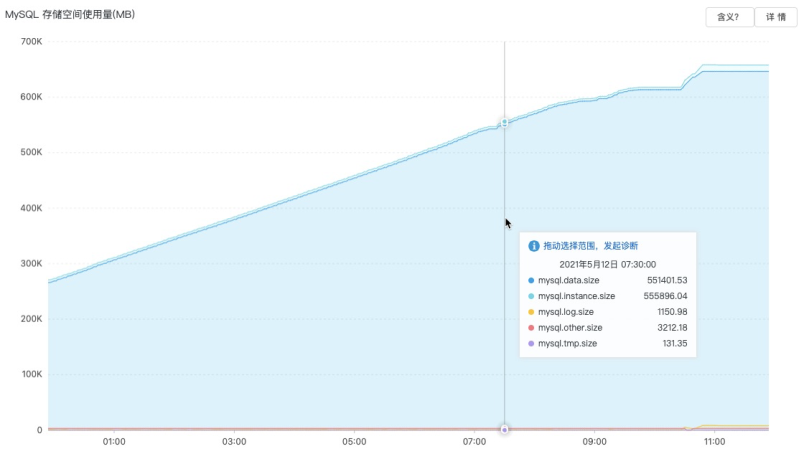
图15. 线上RDS-MySQL空间扩容效果示意图